The previous two chapters named the CxPU as the architectural unit of context processing and described its operation as functional generation on a sealed composition. Both chapters treated neural inference as the implicit substrate. This chapter makes the substrate-independence of the abstraction explicit. The CxPU is defined by its interface, not its implementation. Anything honoring the interface — human-readable input, human-readable output, with intent carried through the operation — is playing the role of inference, regardless of what mechanism is doing the work.
The Interface Is the Abstraction
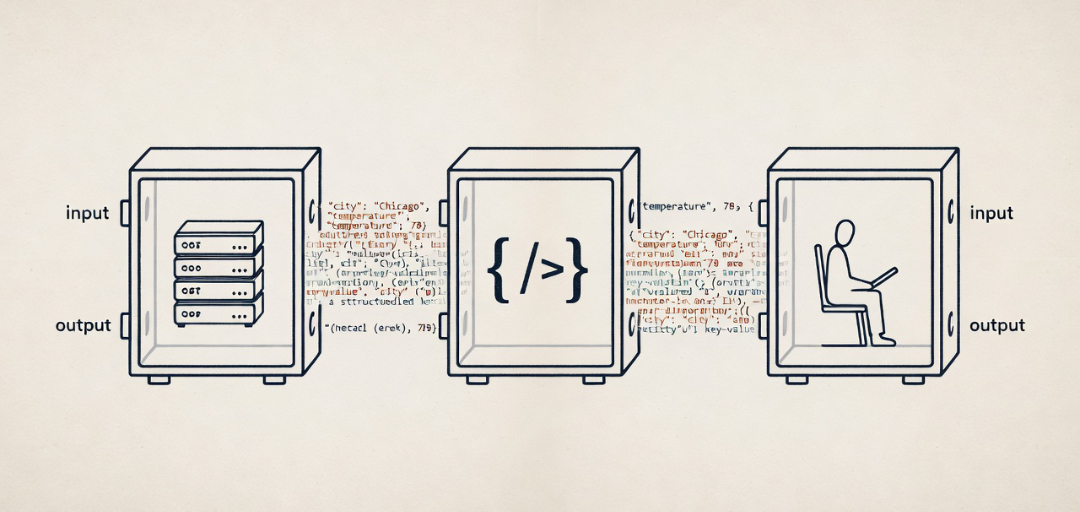
A CxPU reads composed input and produces output that carries intent forward. That is the entire architectural commitment. The internal mechanism is unconstrained. It can be neural inference of any architecture or scale. It can be deterministic code of any complexity. It can be a human being reading and writing. It can be a hybrid of these. The abstraction does not care what fills the role. It cares that the role is filled.
Three cases make this concrete. REST services have been playing the role of inference since text-based input-output became the dominant interchange format for web services. Local deterministic functions honoring a structured text-based input-output contract play the role within a single runtime. Humans performing language-mediated work play the role in organizational and collaborative contexts. Each case demonstrates the same architectural pattern with a different substrate. Together they establish that the framework describes something larger than LLM inference — it describes a general pattern of operations mediated by human-readable intent, and LLMs are one substrate among several that can fill the role.
A Note to Non-Technical Readers
The two technical cases ahead describe specific kinds of software. Readers without a software engineering background may feel this material sits outside what they can personally act on. It does not. By this point in the series, a non-technical reader already knows how to compose a system prompt, write durable intent, and specify what an operation should accept as input, what it should produce as output, and what interpretation it should perform. These are exactly the capabilities required to instruct an LLM to produce a software-based CxPU.
A well-composed system prompt defining a CxPU is enough for an LLM to generate the corresponding software — a REST service, a local function, or the harness code that coordinates them. The technical details of how these implementations work are the LLM's concern. What the reader needs is clarity about what the input context should do at the architectural level, and that clarity is the same composition craft the series has been teaching all along. Read the sections ahead for understanding, not for implementation burden.
REST Services as CxPUs
REST is the pattern web browsers and servers have always used to communicate. When someone types a website address like google.com and the browser loads the homepage, the browser has sent a REST request to a web server asking for that page. The server interprets the request, finds the page, and sends it back as the response. This is REST in its simplest form — a request for a document, a response containing the document. The same pattern handles much more than document fetches. A weather app sends a REST request asking for the forecast and receives structured data back. A payment app sends a REST request to process a transaction and receives confirmation. A chat interface sends a REST request to store a new message. Every one of these is the same structural operation: a request composed with enough information to convey what is wanted, a service that interprets the request and does the work, a response that carries the result back. REST is the dominant pattern for how software components communicate over networks today, from loading a single web page to coordinating the complex exchanges behind every app.
What makes modern REST services act as CxPUs is the format they use to exchange structured information: JSON. JSON is a way of writing structured data as plain text. A piece of JSON looks something like a labeled list — names paired with values, organized in a way both humans and software can read. A JSON response from a weather service might look like this:
{ "city": "Chicago", "temperature": 78, "conditions": "partly cloudy", "humidity": 62 }
The important property of JSON is that it is human-readable. A developer can open a JSON request or response and read it. An operator troubleshooting a problem can inspect the exchange without special tools. An integrator building against an unfamiliar service can see what the service expects and what it returns. The industry could have standardized on more compact binary formats, but JSON won because systems built on an inspectable, human-readable interface are the systems that actually get built, debugged, and maintained at scale.
This is what makes a REST service a CxPU. The request is a composed input in human-readable form, carrying the intent the caller wants the service to act on. The response is output in the same human-readable form, carrying the result back. The service interprets the composed input, performs whatever work its implementation requires, and produces composed output. The interface is exactly the CxPU interface. The substrate performing the work happens to be software running on a server rather than a neural network, but the role it plays is the same role any CxPU plays. Engineers who have been building REST systems have been building CxPU networks the whole time, whether they named them that or not. The vocabulary simply makes visible what was structurally present all along.
LLM inference is commonly provided today as a REST service that interprets requests and returns responses.
Local Deterministic Functions as CxPUs
A function, in programming, is a small self-contained piece of code that takes some input, does something with it, and returns a result. The name comes from mathematics — a function takes a value and gives back another value. In software, functions are the building blocks most programs are constructed from. "Deterministic" means the function always produces the same output for the same input — no randomness, no hidden state, no surprises. Most of the code that runs inside any application is a network of functions calling other functions, each one performing a small well-defined piece of work.
A function can be designed to accept JSON input and produce JSON output, the same way a REST service does. The input specifies what the function should do, and the output carries the result back. For example, a function that looks up the current temperature for a city might accept this input:
{ "method": "getTemperature", "city": "Chicago" }
And return this output:
{ "city": "Chicago", "temperature": 78 }
A function that converts a temperature from Fahrenheit to Celsius might accept this input:
{ "method": "convertToCelsius", "fahrenheit": 78 }
And return this output:
{ "celsius": 25.6 }
In both cases the input tells the function what to do and what data to work with, and the output carries the result back in the same readable format. A function honoring this kind of interface is a CxPU. It takes composed input, interprets what the input is asking for, performs the work, and produces composed output. No network is involved. The function runs inside whatever program called it, returns its result directly, and the calling code continues. The architectural role is defined by the interface, not by whether the CxPU operation crosses a network boundary. A local function honoring the interface plays the CxPU role just as cleanly as a REST service does.
This dissolves a distinction that often confuses people thinking about systems built on LLMs. Systems are often treated as either "LLM applications" or "conventional code," with the two seen as categorically different. The framework shows they are not different at the architectural level. Both are networks of CxPUs. A system that interleaves LLM operations with ordinary function calls is not mixing two kinds of things — it is composing CxPUs of different substrates, all honoring the same interface, all participating in the same architecture of intent flow. The same CxPU can have its substrate changed without architectural consequence: an LLM CxPU can be replaced by an ordinary function CxPU when the work becomes well understood enough to specify mechanically. The interface stays the same. Everything downstream continues to work without modification.
Humans as CxPUs
The same architectural pattern operates at the scale of human cognition. A person reading a specification and producing an implementation is performing the role of a CxPU. A manager composing instructions for a team member is performing the role of an orchestrator. The team member reading those instructions and producing the resulting work — a report, a decision, a deliverable — is performing the role of a worker CxPU. The entire apparatus of organizational coordination through language is a network of CxPUs, each person or team playing the role by reading composed input and producing output that carries intent forward.
The reader is doing this right now. Every AI chat session is a chain of alternating CxPU operations — the human composing a prompt, the model producing a response, the human reading the response and composing the next prompt. Before the model's CxPU operation can run, the human's CxPU operation has already happened. The human read their own accumulated context, interpreted their intent, and produced the output — the prompt — that becomes the model's composed input. The human performed a CxPU operation a moment before the model did. The chat session is a network of two substrates trading handoffs, and the quality of the conversation depends on both of them performing the role well.
The interface requirements hold at this substrate as much as any other. The composed input is the sealed composition the person will operate on. The person's cognition performs the interpretation. The output is what they produce. Intent flows through the operation. The failure modes are the same failure modes that affect LLM-based systems: mission objective drift, intent degradation across handoffs, output that reads as if it were produced for a different request. Organizations are CxPU networks too, and they fail the same way.
What the framework adds to organizational understanding is the same thing it adds to LLM engineering: vocabulary for what was already happening. The CxPU abstraction does not prescribe new organizational practices. It names the structural role that people and teams have always played when they coordinate through language. The names make the pattern visible. Visibility makes the discipline teachable. Teachability makes the architecture reliable.
This also makes something else possible. A non-programmer who understands what a CxPU is can describe the intent of a function they want an LLM to build. Consider the simplest possible example. A person wants a JavaScript function that adds two numbers together. They describe this intent to an LLM:
Write a JavaScript function that takes two numbers as input and returns their sum.
The LLM produces the code. The person did not write JavaScript. They described the function they wanted, and an LLM produced the implementation. Two operations happened in sequence: the human composing intent, the LLM composing code. Neither of them crossed the architectural boundary between specification and implementation. The human stayed above the boundary, working at the level of architectural intent. The LLM worked below the boundary, handling the language and the syntax. The collaboration worked because both parties honored the CxPU interface — human-readable intent provided to the model, human-readable code flowing back. This is the participation the earlier note promised. Any non-programmer who can describe what a function should do can produce working software this way. The architecture of CxPU networks is genuinely accessible, and the access runs through the same composition craft the series has been teaching from the beginning.
The Claim
Three cases. REST services exchanging JSON through HTTP harnesses. Local deterministic functions honoring structured input-output contracts within a single runtime. Humans performing language-mediated work in organizational and collaborative contexts. Each case is a different substrate. Each case honors the same interface. Each case is a CxPU, architecturally indistinguishable from the others at the level where the framework operates.
Modern systems mix substrates freely. LLM calls invoke REST services. REST services wrap deterministic functions. Functions coordinate with human operators for escalation and review. Every one of these interactions is a CxPU handoff. The framework gives the whole network a unified description because the whole network is the same kind of thing at the architectural level. This opens up a clear engineering discipline: design systems as CxPU networks first, then make substrate choices per-operation.
Anything can play the role of inference. The framework has been pointing at this claim from the beginning. This chapter makes it explicit so that every subsequent piece of engineering built on the framework can proceed with the full substrate flexibility the abstraction actually provides.